La page principale #
La vue normale #
À FAIRE
La vue globale #
À FAIRE
La vue lecture #
À FAIRE
Rafraîchir les flux #
Pour profiter pleinement de FreshRSS, il faut qu’il récupère les nouveaux articles disponibles des flux auxquels vous avez souscrit. Pour cela, il existe plusieurs méthodes.
Mise à jour automatique #
C’est la méthode recommandée car il n’y a pas besoin d’y penser, elle se fait toute seule, à la fréquence que vous avez choisi.
Par le script actualize_script.php #
Cette méthode n’est possible que si vous avez accès aux tâches planifiées de la machine sur laquelle est installée votre instance de FreshRSS.
Le script qui permet de mettre à jour les articles s’appelle actualize_script.php et se trouve dans le répertoire app de votre instance de FreshRSS. La syntaxe des tâches planifiées ne sera pas expliquée ici, cependant voici une introduction rapide à crontab qui peut vous aider.
Ci-dessous vous trouverez un exemple permettant la mise à jour des articles toutes les heures.
0 * * * * php /chemin/vers/FreshRSS/app/actualize_script.php > /tmp/FreshRSS.log 2>&1
« Paramètres de configuration du script; Ils sont utilisables simultanément : »
-
Parameter
ajaxhttps://freshrss.example.net/i/?c=feed&a=actualize&ajax=1 Only a status site is returned and not a complete website. Example: “OK” -
Parameter
maxFeedshttps://freshrss.example.net/i/?c=feed&a=actualize&maxFeeds=30 If maxFeeds is set the configured amount of feeds is refreshed at once. The default setting is10. -
Parameter
tokenhttps://freshrss.example.net/i/?c=feed&a=actualize&token=542345872345734 Security parameter to prevent unauthorized refreshes. For detailed Documentation see “Form authentication”.
Online cron #
If you do not have access to the installation server scheduled task, you can still automate the update process.
To do so, you need to create a scheduled task, which need to call a specific URL: https://freshrss.example.net/i/?c=feed&a=actualize (it could be different depending on your installation). Depending on your application authentication method, you need to adapt the scheduled task.
Aucune authentification #
C’est le cas le plus simple, puisque votre instance est publique, vous n’avez rien de particulier à préciser :
0 * * * * curl 'https://freshrss.example.net/i/?c=feed&a=actualize'
Authentification par formulaire #
Dans ces cas-là, si vous avez autorisé la lecture anonyme des articles, vous pouvez aussi permettre à n’importe qui de rafraîchir vos flux (« Autoriser le rafraîchissement anonyme des flux »).
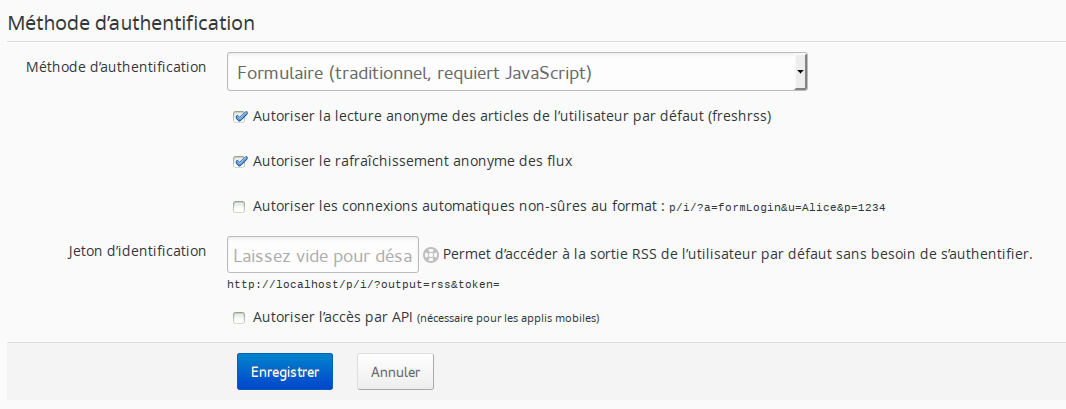
L’url précédente devient donc accessible à n’importe qui et vous pouvez utiliser la tâche cron de la partie précédente.
Vous pouvez aussi configurer un jeton d’authentification pour accorder un droit spécial sur votre serveur.
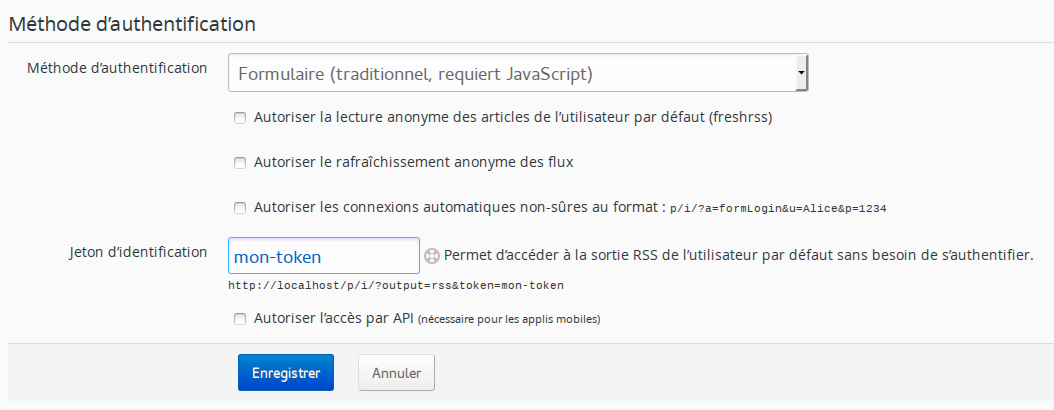
La tâche cron à utiliser sera de la forme suivante :
0 * * * * curl 'https://freshrss.example.net/i/?c=feed&a=actualize&token=mon-token'
You can also target a different user by adding their username to the query
string, with &user=insert-username:
0 * * * * curl 'https://freshrss.exemple.net/i/?c=feed&a=actualize&user=quelquun&token=mon-token'
Authentification HTTP #
Dans ce cas-là, le token et les permissions “anonymes” sont inutilisables et il vous sera nécessaire d’indiquer vos identifiants dans la tâche cron. Notez que cette solution est grandement déconseillée puisqu’elle implique que vos identifiants seront visibles en clair !
0 * * * * curl -u alice:motdepasse123 'https://freshrss.exemple.net/i/?c=feed&a=actualize'
Mise à jour manuelle #
Si vous ne pouvez pas ou ne voulez pas utiliser la méthode automatique, vous pouvez le faire de façon manuelle. Il existe deux méthodes qui permettent de mettre à jour tout ou partie des flux.
Mise à jour complète #
Cette mise à jour se fait pour l’ensemble des flux de l’instance. Pour initier cette mise à jour, il suffit de cliquer sur le lien de mise à jour disponible dans le menu de navigation.
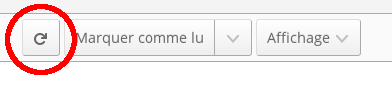
Lorsque la mise à jour démarre, une barre de progression apparait et s’actualise au fur et à mesure de la récupération des articles.

Mise à jour partielle #
Cette mise à jour se fait pour le flux sélectionné uniquement. Pour initier cette mise à jour, il suffit de cliquer sur le lien de mise à jour disponible dans le menu du flux.
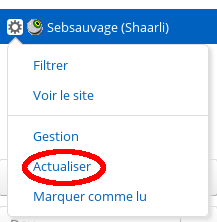
Filtrer les articles #
Avec le nombre croissant d’articles stockés par FreshRSS, il devient important d’avoir des filtres efficaces pour n’afficher qu’une partie des articles. Il existe plusieurs méthodes qui filtrent selon des critères différents. Ces méthodes peuvent être combinées dans la plupart des cas.
Par catégorie #
C’est la méthode la plus simple. Il suffit de cliquer sur le titre d’une catégorie dans le panneau latéral. Il existe deux catégories spéciales qui sont placées en haut dudit panneau :
- Flux principal qui affiche uniquement les articles des flux marqués comme visible dans cette catégorie
- Favoris qui affiche uniquement les articles, tous flux confondus, marqués comme favoris
Par flux #
Il existe plusieurs méthodes pour filtrer les articles par flux :
- en cliquant sur le titre du flux dans le panneau latéral
- en cliquant sur le titre du flux dans le détail de l’article
- en filtrant dans les options du flux dans le panneau latéral
- en filtrant dans la configuration du flux
Par statut #
Chaque article possède deux attributs qui peuvent être combinés. Le premier attribut indique si l’article a été lu ou non. Le second attribut indique si l’article a été noté comme favori ou non.
Dans la version 0.7.x, les filtres sur les attributs sont accessibles depuis la liste déroulante qui gère l’affichage des articles. Dans cette version, il n’est pas possible de combiner les filtres. Par exemple, on ne peut pas afficher les articles lus qui ont été notés comme favori.
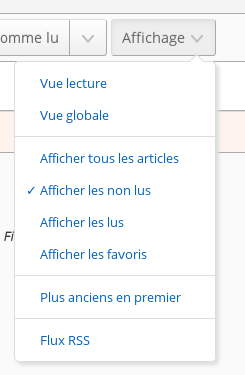
Starting with version 0.8, all attribute filters are visible as toggle icons. They can be combined. As any combination is possible, some have the same result. For instance, the result for all filters selected is the same as no filter selected.

By default, this filter displays only unread articles
By content #
It is possible to filter articles by their content by inputting a string in the search field.
Grâce au champ de recherche #
Il est possible d’utiliser le champ de recherche pour raffiner les résultats :
- par ID de flux :
f:123ou plusieurs flux (ou) :f:123,234,345 - by ID de catégorie :
c:23ou plusieurs catégories (ou):c:23,34,45 - par auteur :
author:nomouauthor:'nom composé' - par titre :
intitle:motouintitle:'mot composé' - par texte (contenu) :
intext:motouintext:'mot composé' - par URL :
inurl:motouinurl:'mot composé' - par tag :
#tagou#'tag avec espace' - par texte libre :
motou'mot composé' - par date d’ajout, en utilisant le format ISO 8601 d’intervalle entre deux dates :
date:<intervalle-de-dates>- D’un jour spécifique, ou mois, ou année :
date:2014-03-30date:2014-03ordate:201403date:2014
- D’une heure spécifiée d’un jour donné :
date:2014-05-30T13date:2014-05-30T13:30
- Entre deux dates :
date:2014-02/2014-04date:2014-02--2014-04date:2014-02/04date:2014-02-03/05date:2014-02-03T22:00/22:15date:2014-02-03T22:00/15
- Après une date donnée :
date:2014-03/
- Avant une date donnée :
date:/2014-03
- Pour une certaine durée après une date donnée :
date:2014-03/P1W
- Pour une certaine durée avant une date donnée :
date:P1W/2014-05-25T23:59:59
- Pour une certaine durée avant maintenant (la barre oblique finale est facultative) :
date:P1Y/ordate:P1Y(depuis un an)date:P2M/(depuis deux mois)date:P3W/(depuis trois semaines)date:P4D/(depuis quatre jours)date:PT5H/(depuis cinq heures)date:PT30M/(depuis trente minutes)date:PT90S/(depuis 90 secondes)date:P1DT1H/(depuis un jour et une heure)
- Depuis le plus ancien jusqu’à une période donnée avant maintenant :
!date:P1M(plus ancien qu’un mois avant maintenant, en utilisant une négation)- Note : la syntaxe
date:/P1M
- Note : la syntaxe
- Les contraintes de date peuvent être combinées :
date:P1Y !date:P1M(depuis un an avant maintenant jusqu’à un mois avant maintenant)
- D’un jour spécifique, ou mois, ou année :
- par date de publication, avec la même syntaxe :
pubdate:<date-interval> - par date de modification par le serveur, avec la même syntaxe :
mdate:<date-interval> - par date de modification par l’utilisateur (par exemple marqué comme lu ou favori), avec la même syntaxe :
userdate:<date-interval> - par ID d’étiquette :
L:12ou de plusieurs étiquettes :L:12,13,14ou avec n’importe quelle étiquette :L:* - par nom d’étiquette :
label:étiquette,label:"mon étiquette"ou d’une étiquette parmi une liste (ou) :labels:"mon étiquette,mon autre étiquette" - par plusieurs noms d’étiquettes (et) :
label:"mon étiquette" label:"mon autre étiquette" - par ID d’article (entrée) :
e:1639310674957894ou de plusieurs articles (ou) :e:1639310674957894,1639310674957893 - par nom de filtre utilisateur (recherche enregistrée) :
search:maRecherche,search:"Ma recherche"ou par ID de recherche :S:3, ou multiple IDs :S:1,2- en interne, ces références sont remplacées par le filtre utilisateur correspondant dans l’expression de recherche
Attention à ne pas introduire d’espace entre l’opérateur et la valeur recherchée.
Certains opérateurs peuvent être utilisé négativement, pour exclure des
articles, avec la même syntaxe que ci-dessus, mais préfixé par ! ou - :
!f:123, -author:nom, -intitle:mot, -inurl:mot, -#tag, !mot, !date:2019, !date:P1W, !pubdate:P3d/.
Il est également possible de combiner les mots-clefs pour faire un filtrage
encore plus précis, et il est autorisé d’avoir plusieurs instances de :
f:, author:, intitle:, inurl:, #, et texte libre.
Combiner plusieurs critères implique un et logique, mais le mot clef OR
peut être utilisé pour combiner plusieurs critères avec un ou logique : author:Dupont OR author:Dupond
ℹ️ Les recherches sont effectuées sur le code HTML, et les caractères XML spéciaux
<&">sont automatiquement encodés (donc on peut chercher'A & B'sans avoir à encoder le&). Pour chercher des tags HTML, il faut utiliser les recherches regex (voir ci-dessous).
Enfin, les parenthèses peuvent être utilisées pour des expressions plus complexes, avec un support basique de la négation :
(author:Alice OR intitle:bonjour) (author:Bob OR intitle:monde)(author:Alice intitle:bonjour) OR (author:Bob intitle:monde)!((author:Alice intitle:bonjour) OR (author:Bob intitle:monde))(author:Alice intitle:bonjour) !(author:Bob intitle:monde)!(S:1 OR S:2)
ℹ️ Si vous devez chercher une parenthèse, elle doit être échappée comme suit :
\(ou\), ou bien être au sein d’une chaîne de texte entre guillemets comme"a (b)"
Regex #
Les recherches de texte (incluant author:, intitle:, inurl:, #) peuvent utiliser les expressions régulières qui doivent être exprimées comme / /.
Les recherches regex sont sensibles à la casse, mais peuvent être rendues insensibles à la casse avec l’option de recherche i comme : /Alice/i
Le mode multilignes peut être activé avec l’option de recherche m comme : /^Alice/m
ℹ️
author:fonctionne avec un auteur par ligne, ce qui fait que le mode multilignes peut être avantageux, comme :author:/^Alice Doe$/imℹ️
#fonctionne également avec un tag par line, ce qui fait que le mode multilignes peut être avantageux, comme :#/^Hello World$/im
Exemple pour rechercher des articles dont le titre commence par le mot Lol avec un nombre indéterminé de o: intitle:/^Lo+l/i
Exemple pour rechercher des articles dont le contenu est vide : intext:/^\s*$/
Contrairement aux recherches normales, les caractères spéciaux XML <&"> ne sont pas encodés dans les recherches regex, afin de permettre de chercher du code HTML, comme : /Bonjour <span>à tous<\/span>/
ℹ️ Une barre oblique (slash) doit être échappée comme suit :
\/
⚠️ Les détails de syntaxe regex avancée dépendent du moteur regex utilisé :
- Les filtres d’action de FreshRSS comme marquer-automatiquement-comme-lu et mettre-automatiquement-en-favori utilisent PHP preg_match.
- Les recherches regex dépendent de la base de données utilisée :
- Pour SQLite, PHP preg_match est utilisé ;
- Pour PostgreSQL ;
- Pour MariaDB ;
- Pour MySQL.
ℹ️ Même avec PostgreSQL, vous pouvez utiliser
\bpour les limites de mots (et\Bpour l’inverse), car une traduction automatique est effectuée vers\yet\Y.